This is a living document of the horrible things I did to my code base and my mental health. I hope it’s entertaining. In a slightly more hopeful note, some of these bugs are used to train agents.
Bug 0018
When: Aug, 2025
Symptoms: Was trying to reproduce the attention sink thing. This is the expected behavior:
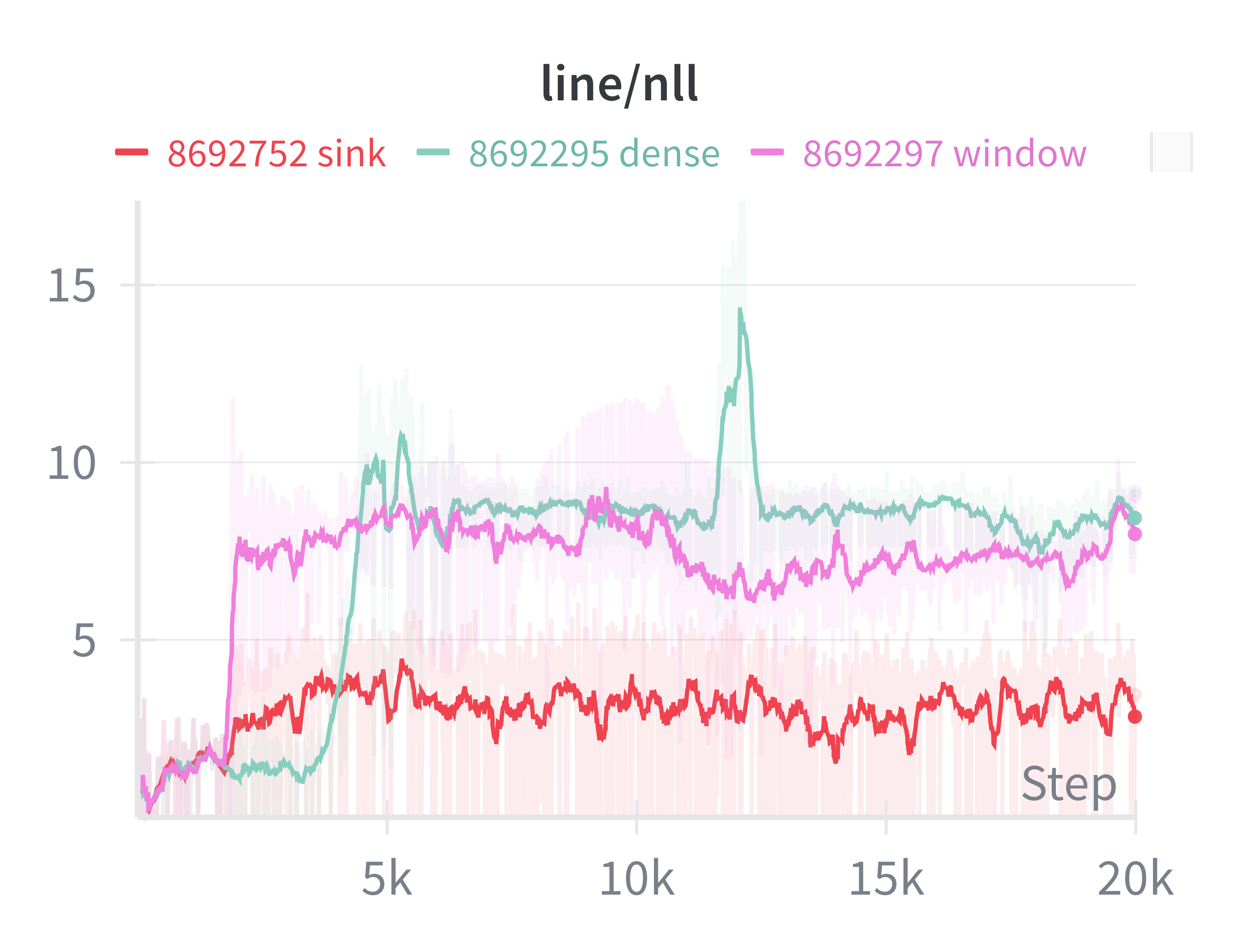
, while what I had was:
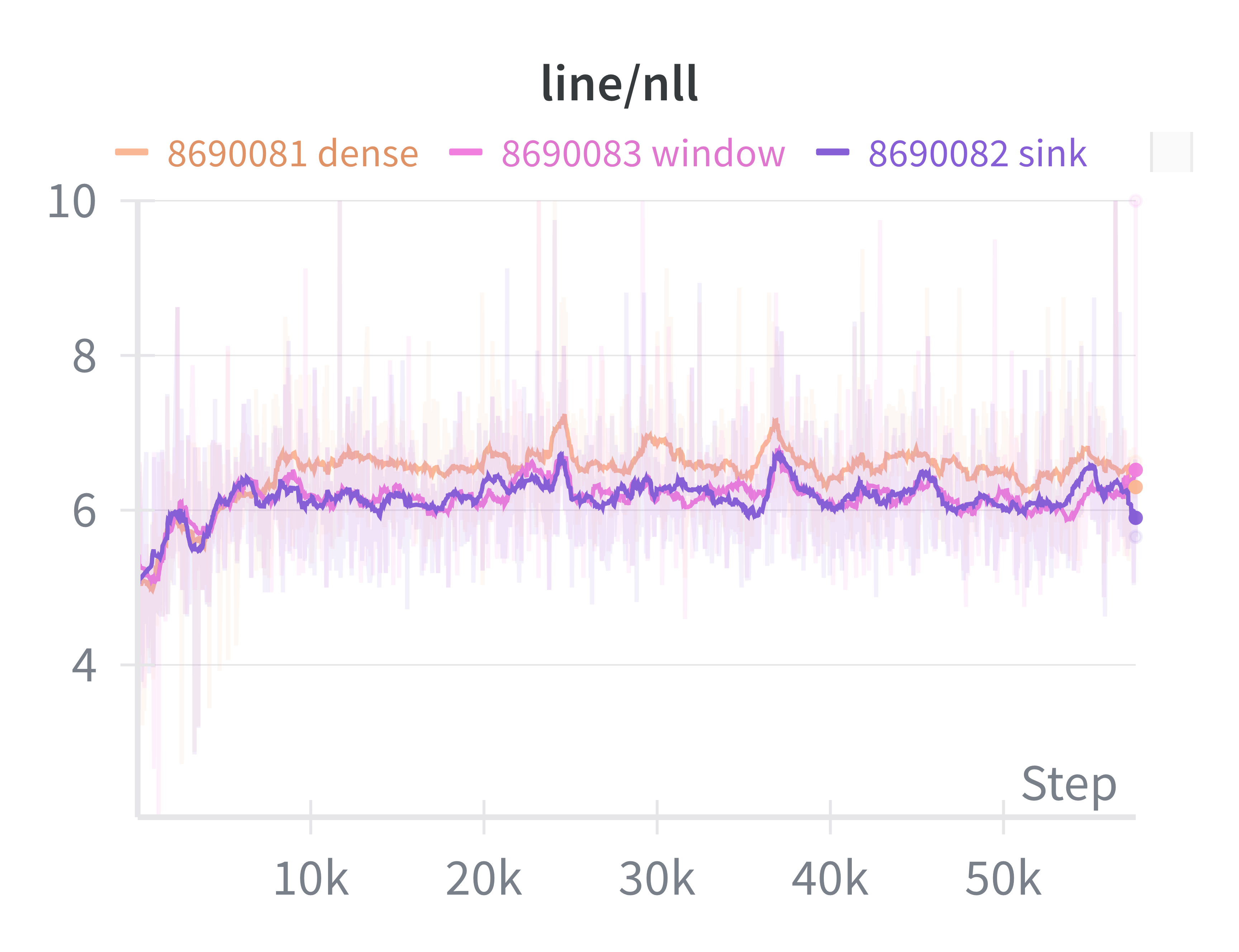
Time taken: a few hours
Solution: Extra <bos> tokens between batches (or 12800). So the correct long token stream is [128000, 74, 8, 3, 99, 425, ...],
but I tokenized chunk by chunk and did not remove the <bos>, so the actual (wrong) token streams become [128000, 74, 8, 3, 128000, 99, 425, ...].
The fact that even the naive dense nll curve too high indicates the issue lied somewhere generic.
Bug 0017
When: Mar, 2025
Symptoms: A mujoco-backed gym env starts omitting WARNING: Nan, Inf or huge value in QACC at DOF 127. The simulation is unstable. Time = 0.0560. after around 1 million simulation steps, and gradually increases to 100%. Cannot reproduce locally in eval.
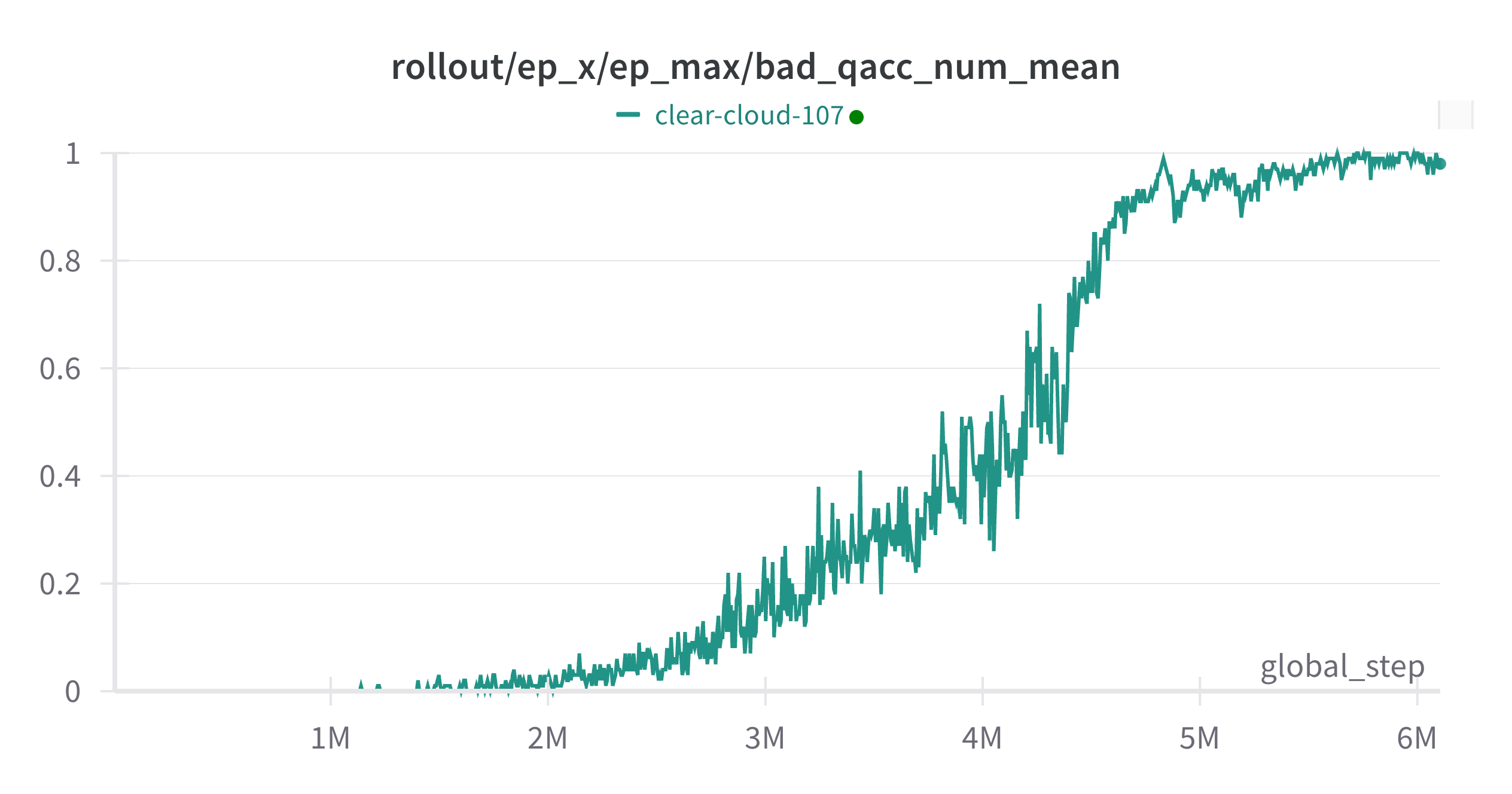
Time taken: 2 days (or actually a couple of weeks)
Solution: It turns out for domain randomization, I had something along this line in the task spec: self.qpos0 += rng.random(-l, l, size=self.qpos0.shape). This accumulates the jiggle every time I call qpos0 = spec.jiggle().qpos0, leading to this time-induced bug.
What made it hard to debug was I made many tradeoffs that sacrifices stability/accuracy for speed. For example,
- I had model.opt.timestep=0.01 (default 0.002).
- I had use the default Euler integrator instead of RK4 (which is supposed to be more stable).
- I imposed a max action force.
- I intended to tune the
solrefparams.
All of these mjcf params can be the culprit leading to bad qacc, but none of these will cause the time-dependency as observed in the plot above. This was a missed hint, and I spent too much time doubting my optimization param tuning.
Another issue was the warning (WARNING: Nan, Inf or huge value...) was piped to MUJOCO_LOG.TXT but had not explicit error throwing in the python environment, yet silently resets to old qpo0. It was extremely helpful to seek visibility from data.warning[mujoco.mjtWarning.mjWARN_BADQACC].number > 0 as suggested in this issue.
Next time, a well-observed measured bug is a half solved one.
Bug 0016
When: Dec, 2024
Symptoms: Freshly installed pip install -U "jax[cuda12]" throws an error with a simple
python -c "import jax.numpy as np; np.array([1,2,3]) - jaxlib.xla_extension.XlaRuntimeError: FAILED_PRECONDITION: DNN library initialization failed. Look at the errors above for more details.
Time taken: one afternoon
Downgrade to jax[cuda12]==0.4.31. I think there was some incompatibility between whatever wheels they are built with, and the drivers we have on g2.
What didn’t work:
- Clear LD_LIBRARY_PATH.
- This was not super helpful.
Minor complaint: Never have I managed to install Jax without pain, local/on g2/on TPU nodes, perhaps with the exception of Colab. It seems like a shared experience for others, others, and others.
Bug 0015
When: Sep, 2024
Symptoms: Times New Roman in matplotlib is lighter (color/weight) than on Overleaf visually
Time taken: 2 days
Solution: Use LaTeX backend for matplotlib, because I reallly don’t want to use tikz. I’m not sure why but sys.path.append didn’t work in this case.
import os
import matplotlib.pyplot as plt
os.environ['PATH'] = '.../texlive/2024/bin/x86_64-linux:' + \
os.environ['PATH']
plt.rcParams['text.usetex'] = True
plt.rcParams['font.family'] = 'serif'
plt.rcParams['text.latex.preamble'] = r'\usepackage{times}'
Bug 0014
When: Sep, 2024
Symptoms: success rate plateaued in deployment after 4 rounds of continual learning
Time taken: 5 days
Solution: Add more LoRA adapters.
Bug 0013
When: June, 2024
Symptoms: val/accuracy had high variance
Time taken: 2 days
Solution: Filter val samples. Remove unreliable ones.
Bug 0012
When: May, 2024
Symptoms: Models are confidently wrong.
Time taken: 2 days
Solution:
- Plot val/loss. My model was massively overfitted. I should have trained for 10 epochs instead of 30 epochs.
- Add regularization by label smoothing, or reducing model complexity (e.g. LoRA target modules).
- Read about model calibration (sequence probability aligned with actual accuracy), plotting reliability diagram. On Calibration of Modern Neural Networks
- Overfitting to loss doesn’t always lead to overfitting to accuracy. How is it possible that validation loss is increasing while validation accuracy is increasing as well
Bug 0011
When: May, 2024
Symptoms: Cannot fit one batch on Idefics2 with 10 images on TPU v4-8
Time taken: 3 hours
Solution: Avg pool image latents https://huggingface.co/HuggingFaceM4/idefics2-8b/discussions/18. Reducing image_seq_length from 64 to 32 allows me to feed 3 examples in one batch.
Bug 0010
When: May, 2024
Symptoms: Shape in compatibility in the backward pass in torch_xla. Similar to this
Time taken: 3 hours
Solution: Idefics2 had funny ways of expanding image tokens. I’m not sure why but using a longer max_length for sequence helped.
Bug 0009
When: Apr, 2024
Symptoms: Could not use all four chips on a TPU v4-8 device with accelerate library.
Time taken: 5 hours
Solution: Set num_processes=null in default accelerate config. This will pass to xmp.spawn for multi-process scripts, which signals null for all chips available.
How: Stepping through tutorials like this. And really understand the mapping of one chip per process.
Bug 0008
When: Apr, 2024
Symptoms: Shape mismatch error in backward path when gradient checkpointing. Similar to this.
Time taken: 2 hours
Solution: Do not use_cache if gradient checkpointing is enabled. PR
How:
- Omer pointed out this shape error is due to gradient checkpointing.
- Notice that previously Idefics had a similar patch to disable
use_cache.
Bug 0007
When: Apr, 2024
Symptoms: Cannot find devices on TPU v4-32 VMs. Specifically, TPU driver finds the devices (/dev/accel* exists) but no worker joins the slice (times out after 15m).
Time taken: 3 days
Solution:
- Use the recommended runtime tpu-ubuntu2204-base.
- Follow the correct tutorial. I was following Run a calculation on a Cloud TPU VM using PyTorch but actually v4-8 is a VM instance but v4-32 is a pod. So Run PyTorch code on TPU Pod slices is the one to go.
- A pod and a single VM are difference because a pod needs multiprocessing (kudos Yoav), and
xm.xla_device()cannot stand alone in global scope. - So really, follow the correct tutorial solved the problem.
How:
sudo lsof -w /dev/accel0- TPU logs
cat /tmp/tpu_logs/tpu_driver.INFOandTPU_STDERR_LOG_LEVEL=0 TPU_MIN_LOG_LEVEL=0 - XLA logs
PT_XLA_DEBUG=1and XLA trouble-shooting guidelines
Bug 0006
When: Mar, 2024
Symptoms: Cannot reproduce training results with/without gradient accumulation
Time taken: One week
Solution:
- Set seed before model initialization.
- Disable dropout layers (in the base model as well as the adapters). BatchNorm is also grad-accum unsafe.
- CrossEntropyLoss (with reduce=’mean’ by default) may not be averaged if the -100 masks are applied to the targets.
- Play with
dtype. Floating point errors arise when I try to compute the loss infloat32vsfloat16. It makes things more complicated in gradients because I also used QLoRA. - Give up because training is only tractable with QLoRA in my case.
How: Observe numerical values. Set up two debuggers side by side.
Bug 0005
When: Mar, 2024
Symptoms: None. Agony from slow training of a language task.
Time taken: Two months
Solution:
- Instead of a fixed max sequence length, use dynamic padding.
- After getting the attention mask from the processor, reset attention mask of padding tokens to zero.
How: Observe numerical values.
Bug 0004
When: Mar, 2024
Symptoms: Cannot reproduce training results on the same hardware using the same configuration and seed.
Time taken: One day
Bug 0003
When: Feb, 2024
Symptoms: Cannot reproduce training results on the same hardware using the same configuration and seed. Train loss curves were close in the first 3 epochs, but diverged after. Same for validation curves.
Time taken: Two days
Solution: Downgrade transformers library.
How: Talk to kind experts
Bug 0002
When: Sometime in fall 2023
Symptoms: My chat bot serving online and offline gave different responses to the same requests.
Time taken: Two days
Solution: Online and offline models used different pre-processors.
How: Observe numerical values flowing into serving vs evaluation pipeline.
Bug 0001
(Fingers crossed I will not overflow 9999)
When: Sometime in spring 2020
Symptoms: I was building a prototype mobile robot. Voltage between one motor was consistently lower than expected.
Time taken: One hour
Solution: I put one battery in reverse.
How: Ask for help from TA